
Learn: Deep Dive
Claude Code Skills: Build Reusable Team Playbooks

Sergey Kaplich
AI inference is the process of using a trained machine learning model to make predictions on new data—essentially running your ML model in production. Think of it like deploying a web API that takes input data, processes it through a neural network instead of business logic, and returns predictions as JSON responses. The key difference from training is that inference focuses on speed and efficiency rather than learning, serving real-time requests for applications like search recommendations, fraud detection, or language translation.
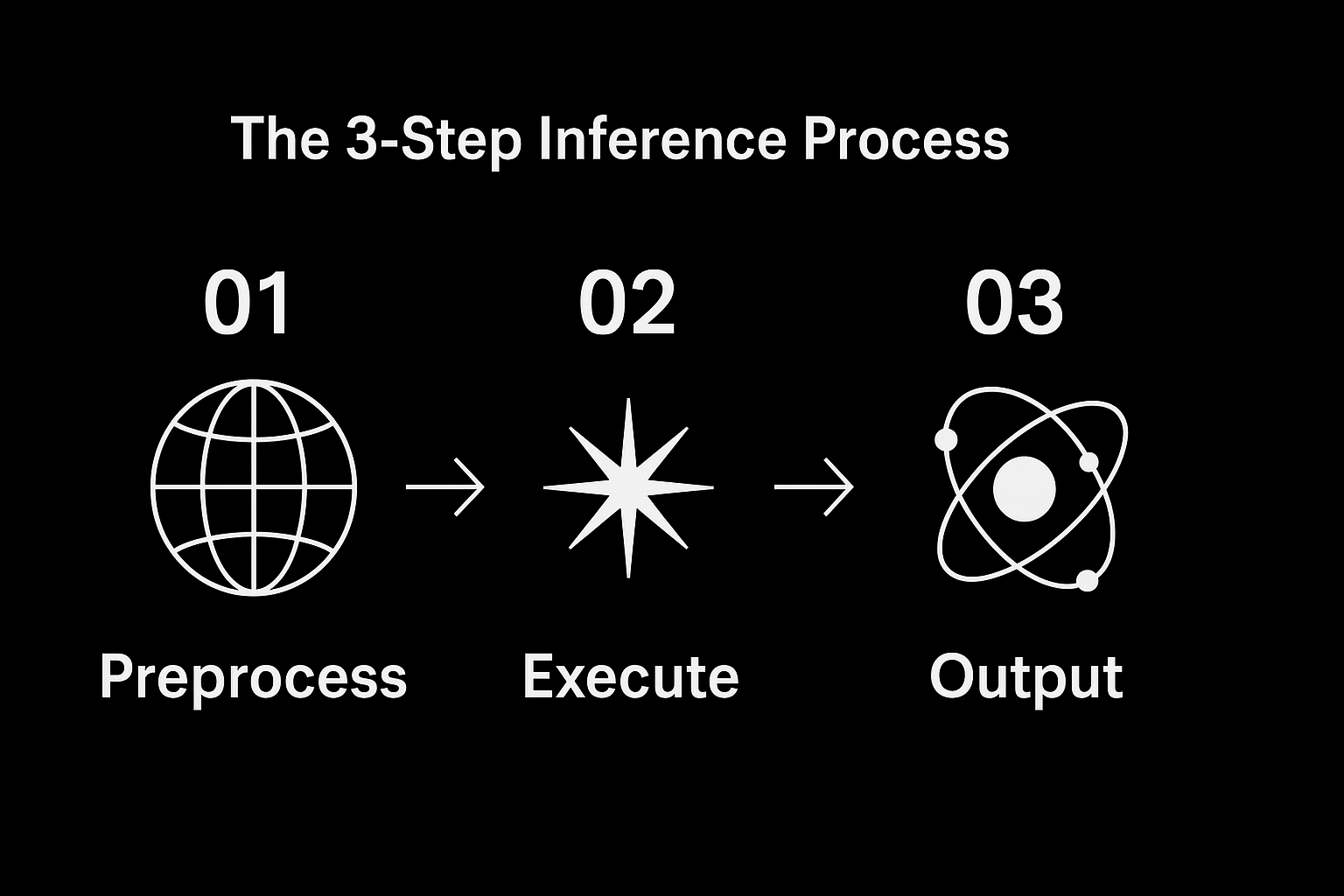 Inference in 3 steps
Inference in 3 steps
AI inference operates through familiar web service patterns that developers already understand. When you deploy a machine learning model, you're essentially creating a specialized API endpoint that processes requests through neural networks rather than traditional application logic. The technical implementation follows a standard three-step request-response cycle: input preprocessing (data validation and transformation), model execution (running the neural network computation), and output post-processing (formatting results for your application).
The architectural patterns mirror web service deployment exactly. Models run in Docker containers, integrate with API gateways, support auto-scaling based on traffic, and return standard HTTP status codes with JSON responses. Production systems use the same monitoring, logging, and error handling approaches you'd implement for any REST API. The main difference lies in the computational work happening inside each request—instead of database queries and business logic, you're running matrix operations optimized for GPUs.
Three deployment approaches solve different architectural requirements. Real-time inference serves individual requests with sub-second latency, perfect for user-facing features like chat interfaces or recommendation engines. Batch inference processes large volumes of data asynchronously, ideal for analytics workloads where you can trade latency for cost efficiency—think processing all customer transactions overnight. Edge inference runs models directly on user devices, eliminating network latency entirely and providing privacy benefits, commonly used in mobile apps and IoT devices.
Performance optimization requires understanding that memory bandwidth often constrains inference more than raw compute power. According to NVIDIA's analysis, memory bandwidth between GPU components frequently becomes the bottleneck before compute capacity limits are reached. Unlike traditional web services where adding more servers linearly improves capacity, AI inference frequently bottlenecks on how fast data moves between GPU memory and processing units. This means optimization focuses first on model-level improvements like quantization (using lower precision numbers) and pruning (removing unnecessary neural network connections) rather than just scaling infrastructure.
The production reality involves more operational complexity than many developers expect. Successful inference deployment requires model versioning systems, A/B testing frameworks for comparing model performance, cost monitoring (GPU time is expensive), and sophisticated caching strategies. However, the optimization techniques are more accessible than commonly believed—quantization can provide 2-4x speed improvements with minimal accuracy loss using standard tools rather than requiring deep mathematical expertise.
Modern cloud platforms abstract much of this complexity through managed services. AWS SageMaker, Google Vertex AI, and Azure ML provide endpoints that handle container orchestration, auto-scaling, and model versioning automatically. These services let you deploy models with a few API calls, then integrate them into applications using standard HTTP requests. For teams getting started, managed services provide the fastest path to production while open-source frameworks like TensorFlow Serving offer more control for custom requirements.
"Adding more GPUs automatically improves inference performance" - In reality, memory bandwidth between GPU components often becomes the bottleneck before compute capacity. Throwing more hardware at the problem can actually hurt performance if not carefully configured. Focus on model optimization first.
"Quantization and pruning inevitably hurt model accuracy" - Modern optimization techniques can reduce model size by 50-75% while maintaining acceptable accuracy when applied systematically. The tooling has matured significantly, making these optimizations accessible rather than requiring research-level expertise.
"Inference scaling works like web service scaling" - While the API patterns are familiar, ML inference requires understanding different parallelism strategies and batching algorithms. Simple horizontal scaling often misses the memory access patterns and GPU utilization considerations that determine actual performance.
Consider building a document search feature for your application. Traditional keyword matching misses relevant results when users search for concepts rather than exact terms. With semantic search through inference:
# User searches for "machine learning tutorial"
search_query = "machine learning tutorial"
# Send to embedding model via API
response = requests.post('/api/embed', json={'text': search_query})
query_embedding = response.json()['embedding']
# Find similar documents in vector database
similar_docs = vector_db.similarity_search(query_embedding, k=10)The embedding model runs inference to convert text into numerical representations that capture meaning. Your application sends HTTP requests to the model endpoint just like any other API call. The model processes the text through neural networks optimized for semantic understanding, returning vector embeddings that enable finding conceptually similar content even when exact words don't match.
This pattern powers GitHub's code search, documentation sites, and e-commerce product discovery. The implementation uses standard web development patterns—REST APIs, JSON responses, caching strategies—while the "business logic" happens through machine learning models rather than traditional algorithms.
Sergey Kaplich
