
Learn: Deep Dive
Claude Code Skills: Build Reusable Team Playbooks

Sergey Kaplich

This week we have a focus on practical systems rather than raw power. New research, tools, and models deliver superior results with fewer resources while fitting seamlessly into existing workflows. With real-time processing, mobile-optimized designs, and AI that actually does things, we're seeing useful applications replace laboratory curiosities.
Key Highlights:
Here are some of the research papers from this that caught our attention:
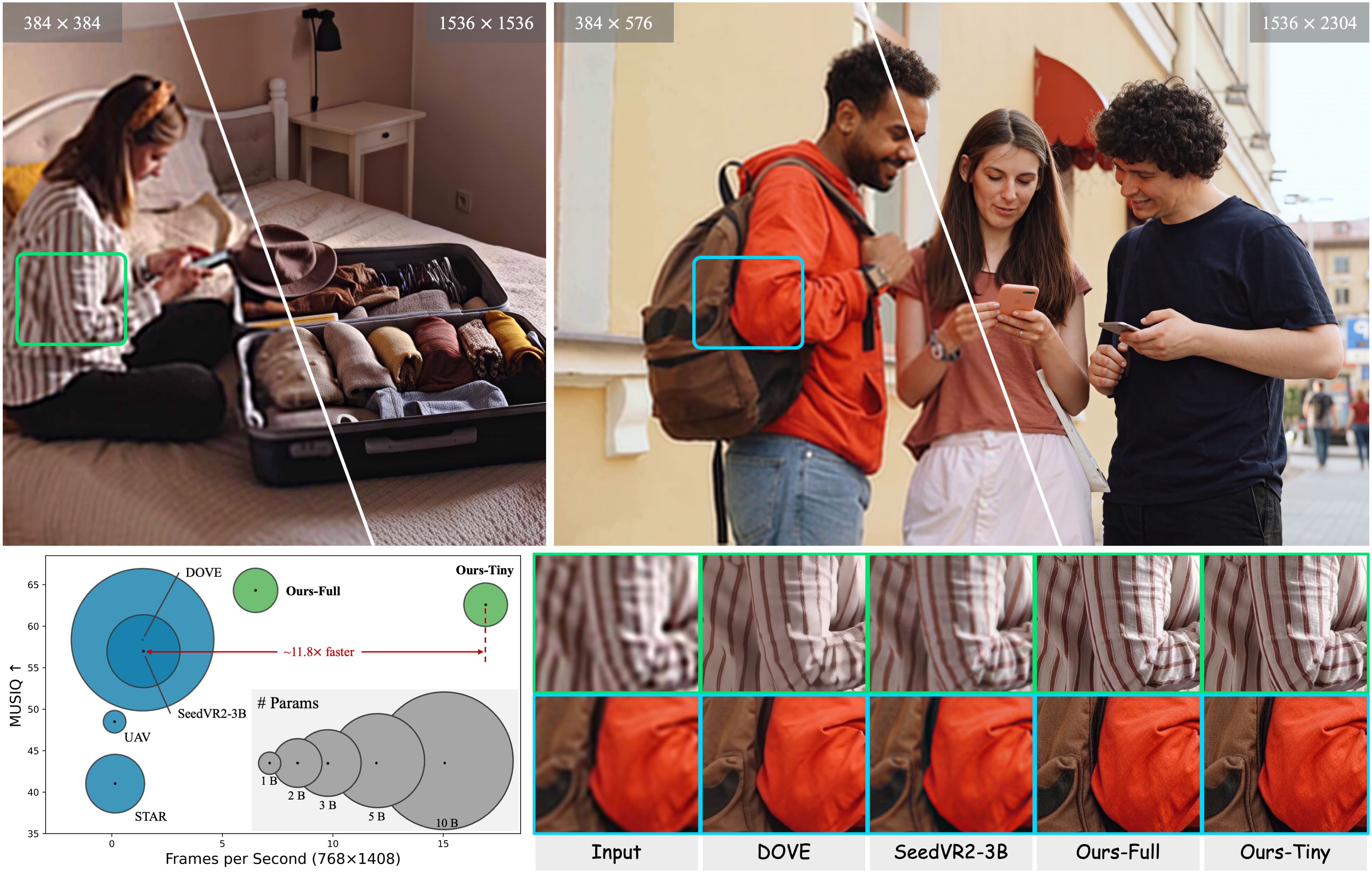
What it is: A video super-resolution system that takes blurry, low-quality videos and sharpens them to high definition in real-time. Think of it like having an "enhance" button that actually works - processing video at 17 frames per second (roughly the smoothness of live TV) at high resolution (768×1408 pixels, about 1080p quality).
Preliminary findings suggest a remarkable 12× speedup over previous methods. Instead of batch processing that kills user experience, you can now enhance video streams as they play.
Why it matters for developers: Real-time video enhancement opens possibilities for live streaming improvements, video conferencing quality boosts, and mobile video processing applications where latency matters more than perfect quality. You can finally build "enhance video quality" features that users will actually use because they don't have to wait.
Problem it solves: Traditional video super-resolution methods are too slow for real-time applications, creating a bottleneck between video quality enhancement and practical deployment - essentially making video enhancement features unusable in production apps.
Results you can expect: FlashVSR reportedly processes 768×1408 videos at approximately 17 FPS while maintaining competitive quality metrics, representing a 12× improvement in processing speed compared to existing state-of-the-art methods.
Future implications: This efficiency breakthrough suggests we're approaching the point where real-time video enhancement becomes standard in consumer applications and live streaming platforms.
What it is: A vision-language model (an AI that can watch videos and answer questions about them) designed to process extremely long videos - over 2 hours. It demonstrates potential for real-time performance at 8 frames per second on NVIDIA H100 hardware.
Think of it as an AI that can watch an entire movie and then discuss any scene or plot point without forgetting what happened earlier. The system solves memory constraints by processing video like a stream, maintaining context without exploding memory usage.
Why it matters for developers: Most AI video systems struggle with long-form content due to memory constraints (similar to how your app might crash when processing large files). StreamingVLM enables applications like full movie analysis, surveillance video processing, and extended video conferencing understanding without the typical memory limitations.
Problem it solves: Current vision-language models hit memory walls when processing long videos, forcing them to either compress content heavily (losing detail) or process in small chunks that force them to lose track of the overall story.
Results you can expect: Initial results show a 66.18% win rate against GPT-4O mini while sustaining 8 FPS processing speed on videos exceeding 2 hours in length, demonstrating both quality and endurance.
Future implications: Long-form video understanding could revolutionize content moderation, automated video editing, and real-time analysis of extended visual content.
What it is: A new approach to AI image generation that combines three technologies to create better images: First, it uses the same core technology that powers ChatGPT to process information. Second, it uses compression tools that shrink file sizes while keeping important visual details. Third, it uses a gradual image-creation process.
This system creates images that are nearly indistinguishable from real photographs. On the standard quality measurement scale (called FID), it scored 1.51 out of what experts consider excellent (anything under 2).
Why it matters for developers: This represents a significant quality leap in AI image generation, approaching photorealistic results while maintaining computational efficiency. If you're building creative tools, product visualization features, or need synthetic data generation, this gives you much better image quality without requiring massive server resources.
Problem it solves: Current diffusion models often struggle with fine details and computational efficiency, requiring trade-offs between image quality and generation speed - forcing developers to choose between "fast and mediocre" or "slow and good."
Results you can expect: RAE achieves an FID score of 1.51 for 256×256 images without guidance and 1.13 with guidance, representing state-of-the-art performance on standard image generation benchmarks.
Future implications: As image generation quality approaches indistinguishable from photography, we'll need new frameworks for authenticity verification and creative attribution.
Note: Code + Paper still to be released
What it is: This system creates high-quality images faster than previous methods - like a Polaroid camera that develops instantly rather than traditional film that needs processing time. Unlike other image generators, it skips the compression step entirely. Unlike other systems, this works directly with image pixels instead of using compression tools as a middle step. This direct approach produces high-quality results while simplifying the entire process.
Why it matters for developers: By eliminating compression tools, this approach reduces the complexity of the generation pipeline while maintaining quality, potentially making image generation more accessible and reducing computational overhead. You get fewer moving parts in your image generation system, which means fewer things that can break.
Problem it solves: Traditional high-resolution image generation relies on compression tools as intermediary representations, adding complexity and potential quality loss in the encoding/decoding process - which reduces image quality at each step.
Results you can expect: The model achieves ImageNet-256 FID scores of 2.04 and ImageNet-512 FID of 2.35 using 75 processing steps, demonstrating competitive performance without compression tool dependency.
Future implications: Simplified generation pipelines could democratize high-quality image synthesis and enable new applications in resource-constrained environments.
What it is: A compact model architecture using just 7 million parameters (roughly the size of a small mobile app) that shows potential for 45% accuracy on the challenging ARC-AGI-1 benchmark (a test of abstract reasoning that typically stumps much larger AI models) through recursive processing patterns (like solving a puzzle by breaking it into smaller, similar puzzles).
Why it matters for developers: This demonstrates that intelligent behavior doesn't always require massive models, opening possibilities for on-device AI and edge computing applications where memory and power are constrained. You can now build reasoning features that run locally on smartphones instead of requiring expensive API calls to cloud services.
Problem it solves: The assumption that complex reasoning requires large models creates barriers for deploying AI in mobile devices, embedded systems, and resource-limited environments - essentially making smart features unavailable to users without high-end hardware or constant internet connectivity.
Results you can expect: Despite using only 7M parameters, the model achieves 45% test accuracy on ARC-AGI-1, a benchmark designed to test abstract reasoning capabilities that typically challenge much larger models.
Future implications: Recursive architectures could enable sophisticated reasoning in smartphones, IoT devices, and other edge computing scenarios previously thought impossible.
What it is: A quantization technique (a method of compressing AI models by using smaller numbers, like converting high-resolution images to lower file sizes) that enables training 32 billion parameter reinforcement learning models on single H100 80GB GPUs. The system can solve 9 out of 10 math word problems correctly - the kind of reasoning tasks that typically require expensive supercomputer clusters - achieving 90.8% accuracy on mathematical reasoning tasks (GSM8K).
Why it matters for developers: Large-scale RL training typically requires expensive multi-GPU setups costing hundreds of thousands of dollars. QeRL democratizes access to powerful RL training, making it feasible for smaller research groups and companies to develop sophisticated AI agents on more reasonable hardware budgets.
Problem it solves: Memory requirements for large RL model training often exceed single GPU capacity, forcing developers into expensive distributed training setups or smaller, less capable models - like being forced to use a supercomputer cluster when you just need a powerful workstation.
Results you can expect: QeRL achieves 90.8% accuracy on GSM8K mathematical reasoning while enabling >1.5× rollout speedup and fitting 32B parameter models on single H100 80GB GPUs through quantization techniques.
Future implications: More accessible large-scale RL training could accelerate development of autonomous agents, robotics applications, and complex decision-making systems.
What it is: An optimization technique that early research indicates can reduce inference time (how long the AI takes to think and respond) by 90% while improving accuracy by up to 28.1% through streamlined reasoning pathways in language models. It's like finding shortcuts in a maze that are not only faster but also lead to better destinations.
Why it matters for developers: This addresses the fundamental trade-off between reasoning quality and speed, potentially making sophisticated AI reasoning practical for real-time applications like customer service chatbots, tutoring systems, and interactive assistants where users expect immediate responses.
Problem it solves: Complex reasoning tasks typically require significant computational time (often several seconds per response), making them impractical for applications that need immediate responses or operate under strict latency constraints - like trying to use a thoughtful but slow customer service representative during peak hours.
Results you can expect: LightReasoner demonstrates up to 28.1% accuracy improvement alongside 90% inference time reduction across multiple reasoning benchmarks, showing that efficiency and performance can improve simultaneously.
Future implications: Efficient reasoning could enable deployment of sophisticated AI decision-making in latency-critical applications from autonomous vehicles to high-frequency trading systems.
What it is: An open-source framework from Sakana AI that uses large language models to evolve programs and algorithms automatically. Instead of traditional genetic programming approaches, it leverages LLM reasoning to guide the evolution process with superior sample efficiency.
Why it matters: Traditional program synthesis requires extensive computational resources and often produces suboptimal solutions. ShinkaEvolve addresses this by using LLMs' understanding of code patterns to make smarter evolutionary choices, dramatically reducing the search space for complex programming problems.
Key features:
Getting started: The framework integrates with existing Python ML pipelines and provides YAML configuration for different evolution strategies.
Adoption signals: Released by Sakana AI research team with active development on GitHub, gaining traction in the automated programming research community.
What it is: Meta's 1.08 billion parameter language model specifically designed for mobile deployment, featuring a 128k token context window with near-lossless int4 quantization. Built for both CPU and accelerator inference on resource-constrained devices.
Why it matters: Most language models require server-grade hardware, making local deployment expensive and impractical. MobileLLM-Pro delivers competitive performance while running efficiently on smartphones and edge devices, enabling privacy-preserving AI applications without cloud dependencies.
Key features:
Getting started: Available through Hugging Face Transformers with mobile-specific inference examples and quantization scripts.
Adoption signals: Available through Hugging Face Transformers with active downloads from mobile development teams. Meta's continued investment in mobile AI indicates long-term support.
Anthropic launched their plugin system for Claude Code that allows developers to install custom slash commands, agents, MCP servers, and development hooks. Currently in public beta with single-command installation for popular development tools.
AI coding assistants often feel disconnected from actual development workflows. Claude Code Plugins solve this by integrating directly with existing tools and processes, turning Claude into a programmable development environment rather than just a chatbot.
Key features:
Example commands:
# Install development plugin
/install code-review-agent
#Create custom slash command
/create-command /test "Run unit tests with coverage"
#Set up workflow hook
/hook deploy "Review code changes before deployment"Getting started: Access through Claude Code's interface with /install command for community plugins, or build custom plugins using the documented API.
Adoption signals: Public beta launch indicates Anthropic's commitment to developer workflows. Early adoption from development teams seeking AI-first tooling integration.
What it is: A GitHub-based platform that runs nightly performance tests on open-source inference frameworks, tracking metrics like throughput, latency, and memory usage across models including Llama 70B and DeepSeek R1.
Why it matters: Choosing the right inference framework involves complex trade-offs between speed, memory usage, and accuracy. InferenceMAX provides real-time, standardized benchmarks that help developers make data-driven infrastructure decisions rather than relying on vendor claims.
Key features:
Getting started: View benchmarks at the GitHub repository, with API access for programmatic integration into deployment pipelines.
Adoption signals: Growing usage by ML infrastructure teams for framework selection. Community contributions expanding model and framework coverage.
What it is: An open-source framework that enables AI agents to automatically test target models across multi-turn scenarios, specifically designed to surface concerning behaviors like autonomous deception and oversight subversion that traditional testing might miss.
Why it matters: As AI systems become more autonomous, traditional testing approaches fail to catch subtle safety issues that emerge in complex, multi-step interactions. Petri automates the discovery of these edge cases through systematic adversarial testing.
Key features:
Getting started: Install via pip and configure test scenarios using YAML files. Includes pre-built test suites for common safety concerns.
Adoption signals: Developed for AI safety research community with adoption by organizations implementing responsible AI practices. Active development with contributions from safety researchers.
What it is: A framework for building retrieval-augmented generation and agentic AI applications through composable RAG pipelines that can be configured entirely through YAML files without custom code.
Why it matters: Building production RAG systems typically requires extensive custom development and pipeline management. LlamaFarm abstracts this complexity into configuration files, letting developers focus on data and use cases rather than infrastructure plumbing.
Key features:
Example configuration:
rag_pipeline:
retriever:
type: vector_db
source: documents/
generator:
model: llama-3
context_window: 8192
agents:
- name: summarizer
tools: [search, extract]Getting started: Create a YAML configuration file defining your data sources and RAG pipeline, then run with a single command.
Adoption signals: Growing adoption among teams building knowledge management and customer support applications. Active community contributing connectors for popular data sources.
What changed: Anthropic released Claude Haiku 4.5, a compact model that demonstrates superior performance to the larger Claude Sonnet 4 in specific computer use scenarios. This challenges traditional assumptions about model scaling and task-specific optimization.
Why it matters: The performance inversion between small and large models represents a significant shift in AI architecture philosophy, suggesting that specialized training can outweigh raw parameter count. This has major implications for deployment costs and efficiency in production environments.
Key details:
Sergey Kaplich

{kind=link}