
Learn: Deep Dive
Claude Code Skills: Build Reusable Team Playbooks

Sergey Kaplich

ClickHouse is a columnar database designed for real-time analytics that trades operational complexity for exceptional query performance and cost efficiency. It excels at analytical workloads requiring sub-second response times on large datasets but is unsuitable for transactional applications. Choose ClickHouse when you need fast analytics at scale and have the technical expertise to manage its operational requirements, otherwise consider managed cloud alternatives like BigQuery or Snowflake.
When your application starts handling millions of events per day and users expect sub-second analytics dashboards, traditional databases hit a wall. Row-based systems like PostgreSQL excel at retrieving individual records but struggle when aggregating millions of rows for analytics queries. This is where ClickHouse solves the problem.
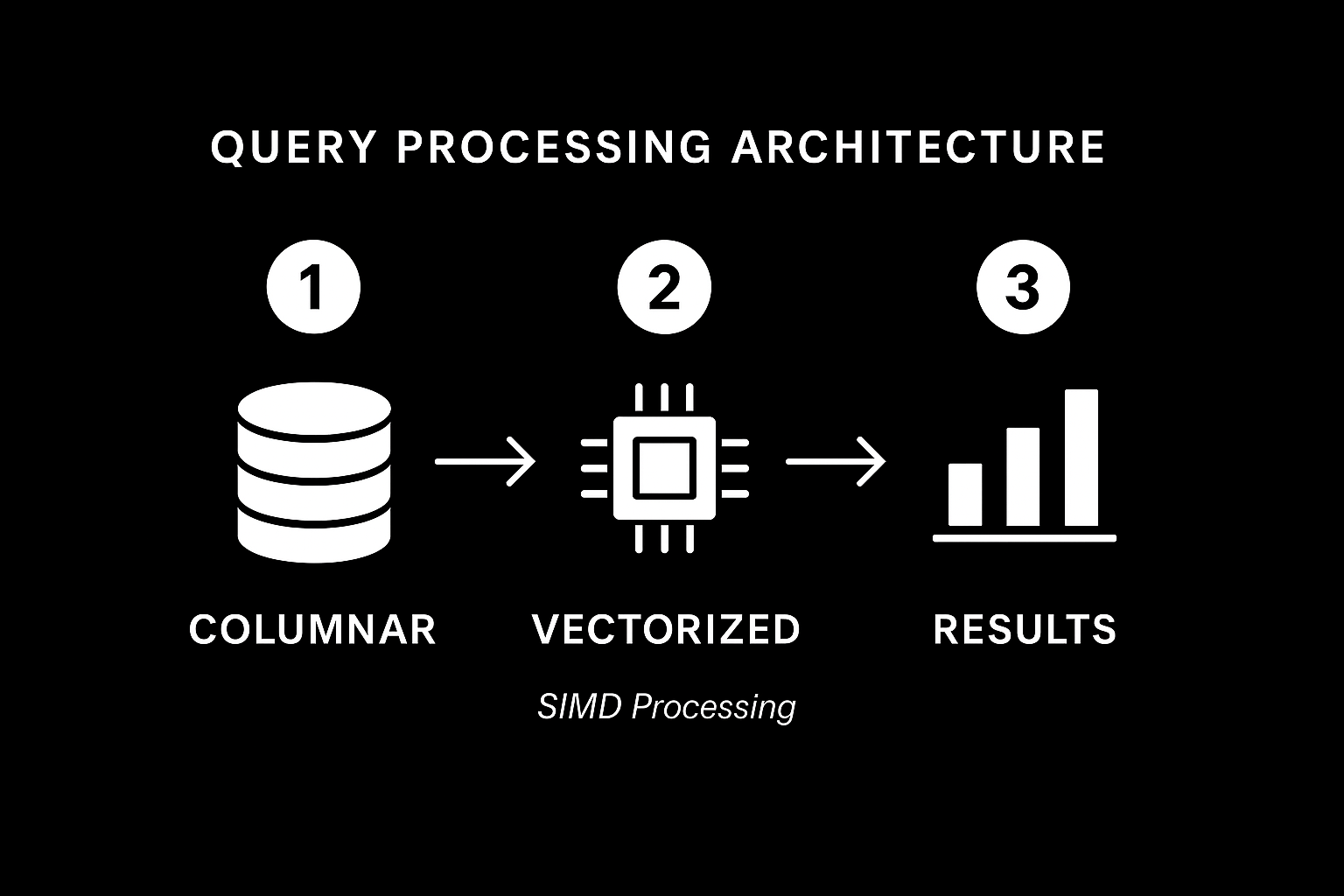
ClickHouse is a columnar database built for fast analytics queries (OLAP workloads). Unlike traditional row-based databases that store data record by record, ClickHouse organizes data by columns, making it exceptionally fast at analytical queries that scan large datasets.
The Problem It Solves
Traditional databases store complete rows together on disk. When you want to calculate the average revenue across millions of transactions, the database has to read entire rows just to access the revenue column. ClickHouse stores all revenue values together, reducing the data it needs to read from disk.
Where It Fits in the Ecosystem
ClickHouse occupies a specific niche in the database landscape. It's not a replacement for PostgreSQL in your transactional systems, but rather a specialized tool for analytical workloads. Think of it as the analytical counterpart to your operational databases.
ClickHouse emerged from Yandex's need to process billions of web analytics events in real-time. The system's architecture reflects this origin through three core design principles:
Columnar Storage with Vectorized Execution
The database processes data in blocks of 65,536 rows, utilizing CPU SIMD (Single Instruction, Multiple Data) instructions for parallel processing. This means when calculating sums or averages, ClickHouse can perform multiple operations simultaneously rather than processing values one by one.

Shared-Nothing Architecture
This distributed design enables massive parallel processing (MPP):
Advanced Compression
ClickHouse achieves compression ratios of 3x-5x on real-world datasets by storing similar data types together. Columns containing mostly zeros, repeated values, or sequential numbers compress exceptionally well.
ClickHouse provides comprehensive SQL support based on ANSI standards, making it accessible to developers familiar with traditional databases. The system supports standard clauses (SELECT, INSERT, CREATE, GROUP BY, ORDER BY), various JOIN operations, subqueries, and window functions.
-- Standard analytical query
SELECT
toDate(event_time) as date,
event_type,
COUNT(*) as event_count,
COUNT(DISTINCT user_id) as unique_users
FROM events
WHERE event_time >= now() - INTERVAL 7 DAY
GROUP BY date, event_type
ORDER BY date DESC;The key difference from traditional SQL databases is the mandatory ENGINE clause when creating tables, which determines how data is stored and accessed.
ClickHouse offers data types optimized for analytical workloads:
CREATE TABLE user_events (
user_id UInt64,
event_time DateTime64(3),
event_properties Map(String, String),
revenue Decimal(10,2),
tags Array(String)
) ENGINE = MergeTree()
ORDER BY (user_id, event_time);ClickHouse supports multiple ingestion methods for real-time data processing:
-- Create materialized view for real-time aggregations
CREATE MATERIALIZED VIEW daily_user_stats TO user_daily_summary AS
SELECT
toDate(event_time) as date,
user_id,
COUNT(*) as event_count,
SUM(revenue) as total_revenue
FROM user_events
GROUP BY date, user_id;The MergeTree engine provides the foundation for ClickHouse's performance through several specialized variants:
The quickest way to experiment with ClickHouse is through Docker:
# Pull and run ClickHouse server
docker pull clickhouse/clickhouse-server
docker run -d --name clickhouse-server \
--ulimit nofile=262144:262144 \
-p 8123:8123 -p 9000:9000 \
clickhouse/clickhouse-server
# Connect with client
docker run -it --rm --link clickhouse-server:clickhouse-server \
clickhouse/clickhouse-client --host clickhouse-serverProduction deployments require careful resource planning. ClickHouse performs best with:
These specifications ensure ClickHouse can leverage its vectorized processing capabilities effectively.
-- Events table for analytics
CREATE TABLE events (
timestamp DateTime,
user_id UInt32,
session_id String,
event_type LowCardinality(String),
properties Map(String, String)
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (timestamp, user_id)
TTL timestamp + INTERVAL 12 MONTH;The ORDER BY clause determines how data is sorted on disk, directly impacting query performance. The PARTITION BY clause helps with data management and query pruning.
ClickHouse query performance depends heavily on leveraging its columnar architecture:
-- Efficient: Only accesses needed columns
SELECT user_id, COUNT(*)
FROM events
WHERE event_type = 'purchase'
GROUP BY user_id;
-- Inefficient: SELECT * forces reading all columns
SELECT *, COUNT(*)
FROM events
WHERE event_type = 'purchase'
GROUP BY user_id;Production memory tuning requires balancing several parameters:
max_memory_usage: Approximately 50% of available RAM divided by concurrent queriesmax_bytes_before_external_group_by: 30-50% of max_memory_usage to prevent memory exhaustionFor multi-node deployments, distributed tables coordinate queries across shards:
-- Local table on each node
CREATE TABLE events_local (
timestamp DateTime,
user_id UInt32,
event_type String
) ENGINE = MergeTree()
ORDER BY timestamp;
-- Distributed table spanning all nodes
CREATE TABLE events_distributed AS events_local
ENGINE = Distributed(production_cluster, default, events_local, user_id);TPC-H results demonstrate ClickHouse's analytical performance capabilities:
Companies use ClickHouse for various analytical workloads:
| Capability | ClickHouse | PostgreSQL | BigQuery | Snowflake |
|---|---|---|---|---|
| Query Performance (OLAP) | Excellent | Poor | Very Good | Very Good |
| Query Performance (OLTP) | Poor | Excellent | Poor | Fair |
| Cost Efficiency | High | High | Medium | Low |
| Operational Complexity | High | Medium | Low | Low |
| Real-time Ingestion | Native | Limited | Batch | Good |
ClickHouse is ideal for:
Choose alternatives when:
ClickHouse lacks fundamental OLTP capabilities that limit its applicability:
These constraints make it unsuitable for applications requiring data integrity across multiple operations or extensive data denormalization strategies.
Operational challenges in multi-node deployments include:
Avoid ClickHouse for:
Production ClickHouse deployments require monitoring setup across multiple dimensions:
These metrics provide visibility into both performance bottlenecks and data pipeline health.
-- Monitor resource-intensive operations
SELECT
query,
elapsed,
formatReadableSize(memory_usage) as memory,
formatReadableQuantity(read_rows) as rows
FROM system.processes
WHERE elapsed > 30
ORDER BY memory_usage DESC;Critical production alerts should focus on:
Q: Can ClickHouse replace PostgreSQL for my application? A: No, ClickHouse and PostgreSQL serve different purposes. PostgreSQL excels at transactional workloads (OLTP) with ACID compliance, while ClickHouse optimizes analytical queries (OLAP). Most applications use both: PostgreSQL for operational data and ClickHouse for analytics.
Q: How does ClickHouse handle updates and deletes? A: ClickHouse supports updates and deletes but they're expensive operations requiring full table rewrites. The database is optimized for append-only workloads. For frequently changing data, consider using CollapsingMergeTree or ReplacingMergeTree engines.
Q: What hardware specifications are recommended for ClickHouse? A: ClickHouse performs best with NVMe SSDs, modern multi-core CPUs (16+ cores), and substantial RAM (64GB+). Allocate 80% of system memory to ClickHouse, with network bandwidth being critical for distributed deployments.
Q: How does ClickHouse pricing compare to cloud analytics solutions? A: ClickHouse typically delivers 3-5x cost advantages over managed cloud solutions like Snowflake and BigQuery due to superior compression ratios and resource efficiency, though operational complexity increases.
Q: Can ClickHouse handle real-time streaming data? A: Yes, ClickHouse excels at real-time ingestion through Kafka connectors, HTTP APIs, and materialized views that provide continuous data transformations as new data arrives.
Q: What are the main operational challenges with ClickHouse? A: Key challenges include memory management tuning, distributed query optimization, monitoring complex multi-node deployments, and troubleshooting performance issues that require ClickHouse-specific expertise.
Q: How does ClickHouse compare to traditional data warehouses? A: ClickHouse offers faster query performance and lower costs than traditional warehouses, but requires more operational expertise. It's particularly strong for real-time analytics rather than batch processing workflows.
Q: Is ClickHouse suitable for small teams or startups? A: ClickHouse works well for teams with specific analytical requirements and sufficient technical expertise. Smaller teams might prefer managed cloud solutions initially, adopting ClickHouse as analytical needs grow and cost optimization becomes important.
ClickHouse represents a shift in analytical database architecture, trading operational simplicity for exceptional performance and cost efficiency. Its columnar storage design and vectorized execution engine deliver unmatched speed for analytical workloads, making real-time user-facing analytics feasible at scale.
The database succeeds when teams need sub-second response times on large datasets, cost-effective analytical processing, or high-throughput streaming ingestion. However, it requires specialized expertise and careful architectural planning to realize these benefits effectively.
Sergey Kaplich
